※本記事は旧ブログからの転載記事です(過去投稿日:2020/12/19)
はじめまして。SMARTチームエンジニアの鍋谷と申します。
今回は機械学習の研究開発業務を行ってきた中で、初心者エンジニアの私が感じた点を書きます。
はじめに
まずは簡単に自己紹介します。
- 2019年4月 弥生に入社・・・開発ほぼ未経験で入社
- 2019年6月 開発本部に配属・・・開発研修を受ける
- 2019年11月 テスト自動化チームに配属・・・自動テストの開発・運用を行う
- 2020年4月 SMARTチームに異動・・・機械学習の研究開発業務を行う
機械学習の特徴と、研究開発の重要性
普通プログラムで何かの判断を行いたい!と思ったら、以下のような流れを考えます。
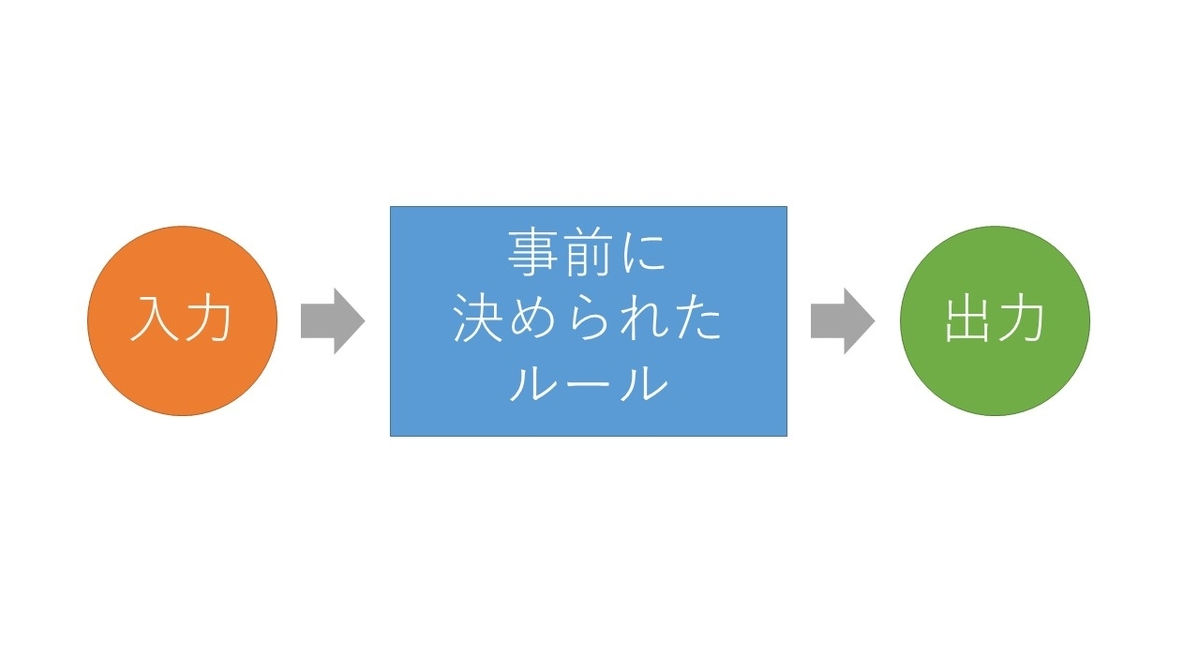 しかし、ルールを事前にはっきりと形にできないものもありますよね。
しかし、ルールを事前にはっきりと形にできないものもありますよね。
そういう場合、仮に最初にルールを決めたとしても、誤って判断されてしまうことが大半でしょう。
機械学習は、「正しい入出力をペアとしたデータをもとに、判断ルールを自動で改善していく手法」です。1
つまり、判断をしてきた経験をもとに、どんどんとルールが改善されていくわけです。
このルール改善の過程を、「学習」と呼びます。
学習の結果どのようなルールができるかは、学習の際に用いるデータや、学習方法の設定などによって異なります。
そして、どのようなときにどのようなルールとなるかを、 一度も学習させずに予測することは難しいです。
つまり、「最終的にどれだけ成果が出るか」は、実際にモデルを動かしていかなければわかりません。
これは普通のプログラムとは異なる、機械学習の大きな特徴です。
とはいえ、どれだけ成果が出るのか全くわからない状態では、会社としてプロジェクトに大きく投資することは難しいでしょう。
だからこそ、実運用するプログラムを作る前に、研究開発でモデルを動かし試行錯誤することが、機械学習のプロジェクトでは特に重要であると考えます。
実運用の状況を想定して研究開発ができていれば、その知見を活かして成果をある程度予測できるでしょう。
これが、私の考える研究開発の重要性です。
研究開発をするために大事なこと
「何を実現したいか」を明確にする
これは機械学習以外のプロジェクトについてもいえることですが、 特に機械学習の研究開発をする上で、「何を実現したいか」を明確にすることは非常に大事だと感じました。 理由は以下です。
「何を実現したいか」で用いる手法が変わる
一口に「機械学習」といっても、古今東西いろいろな手法があります。
そしてこれらの手法はそれぞれに特徴があります。
プロジェクトで何を重視するのかがわかっていないと、最適な手法を選ぶことができません。
たとえば、単純な線形回帰でそれなりの正解率が出る問題について、それなりに正解率が高ければいい、運用コストは抑えたいという場合を考えます。
この場合に、非線形なディープニューラルネットワークをGPU環境で学習してモデルを作成する......といった手法を選択するのは、オーバースペックで高コストとなってしまいます。
このように、「何を実現したいか」を把握してタスクの性質を捉えたうえで、使用する技術を選定することが大事です。
「何を実現したいか」で評価指標が変わる
機械学習の研究開発では、複数のモデルを用意して性能を比較していきます。
このとき、単純に「正解率」をモデルの評価指標とすればいいかというと、必ずしもそうではありません。
単純な二値分類について、予測結果と実際の分類結果をある区分に属するかどうかで整理すると、以下の図のようになります。
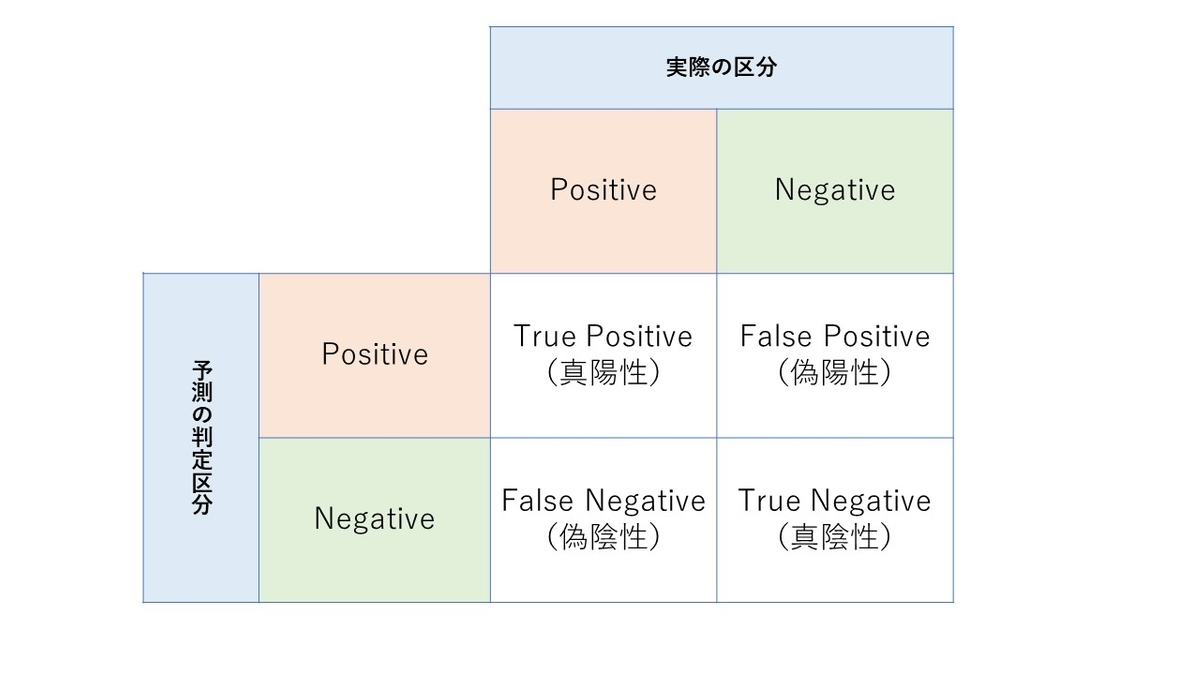 この図において、評価指標は以下のようにいろいろあります。
この図において、評価指標は以下のようにいろいろあります。
- 正解率・・・すべての判定に対する真陽性と真陰性の割合
- 再現率・・・実際の陽性のうち真陽性として検出できたものの割合
- 適合率・・・陽性と判定したもののうち真陽性だったものの割合
そして、最適な評価指標は場合によって異なります。
たとえば「プログラムでコロナウイルスの感染者かどうかを一次予測したい」「陽性の可能性が少しでもある人を逃したくない」という場合であれば、 評価指標として「再現率」を重視します。
一方で、「会計システムで勘定科目を予測したい」「誤った勘定科目には分類したくない」という場合であれば、評価指標として「適合率」を重視します。
このように、ものによって最適な評価の指標は変わります。2
だからこそ、「何を実現したいか」を明確にし、どのような指標で判断すべきなのかを考えなければなりません。
技術動向に常にアンテナを張っておく
機械学習分野は最近ホットな話題ということもあり、非常に研究成果のアップデートが早いです。
技術選定をした2年後にもっといい技術が出た...ということも多々あります。
このため、最新の技術動向がどうなっているかを追っていないと、そのときに最適な手法の選択ができません。
弥生では大学の先生とディスカッションや機械学習に関する勉強会への参加など、 このような技術動向を知る機会をいただいています。これはかなり恵まれていますし、勉強のモチベーションも上がります。
機械学習以外についても知る
運用に乗せるための研究開発をする中では、「機械学習以外の知識」も必要です。
たとえば、モデルの性能比較においては、測定誤差を踏まえて考察を行うなど、統計の知識を持って取り組む必要があります。
また、運用環境の検討では、メモリやCPUなどのリソースの使用状況を監視することが状況改善の考察につながります。
さらに、クラウド上で動かすということであれば、クラウドコンピューティングの知識も必要となります。
機械学習を実際に動かすシステムの全体像がどのようになっているかを知っておくことも、いわずもがな重要です。
このように、「機械学習の研究開発」をするといっても、実際の運用を考えるためには機械学習以外の知識が必要です。
機械学習の知識とエンジニアとしての知識の両方をもっと勉強して、頑張っていきたいです。
さいごに
研究開発は新しく覚えることも考えることも多く、大変刺激的で楽しい業務です。
興味を持っていただけるかたは、採用ページを是非ご覧ください。
www.yayoi-kk.co.jp