この記事は弥生 Advent Calendar 2022の22日目の記事です。
こんにちは🌞弥生でエンジニアをしている野川です。
弥生の開発本部では、AWSへのシステム移行やAWSを利用した業務効率化を進めるため、
去年あたりから会社でAWSの研修を受けられる機会が増えてきています。
そんな中、私も研修で習ったことを活かして(これまで手動で行っていた)Amazon DynamoDBの更新作業の効率化にチャレンジしました! 今回はその内容や感想をお話しできればと思います^^
ちなみにブログ(書くほう)はあまり得意じゃないんですが、これ(↑)だけは設計がめちゃくちゃシンプルで私でも紹介できそうだったので、勢いでエントリーしてしまいました。温かい心でお楽しみください🙏
作業内容の紹介
ではではさっそく紹介していきます。
まず、私の所属する開発チームでは、年に数回DynamoDBのとあるテーブルの更新が必要です。
今回は例として、「master」テーブルでinfoカラムの情報のうち「valid_series_list」の値の更新が必要という状況だとします。
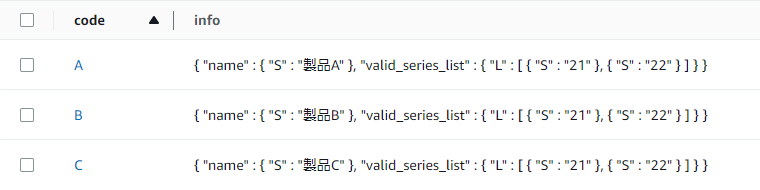
例:
これを
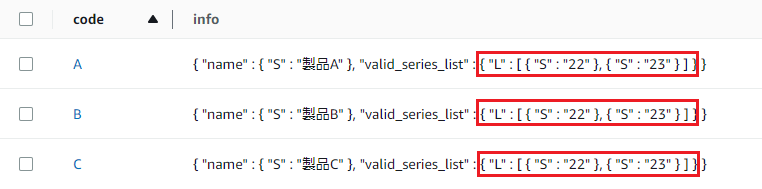
↓ こうしたい!!
これまでのやり方
去年までは、毎回AWS CLIで下記のようなコマンドを実行していました。 一度レコードを削除して、また追加して、という感じです。
例:
# レコード削除
aws dynamodb delete-item --table-name master --key '{"code":{"S":"A"}}' --profile example
aws dynamodb delete-item --table-name master --key '{"code":{"S":"B"}}' --profile example
aws dynamodb delete-item --table-name master --key '{"code":{"S":"C"}}' --profile example
# レコード追加
aws dynamodb put-item --table-name master --item '{"code":{"S":"A"},"info":{"M":{"name":{"S":"製品A"},"valid_series_list":{"L":[{"S":"22"},{"S":"23"}]}}}}' --profile example
aws dynamodb put-item --table-name master --item '{"code":{"S":"B"},"info":{"M":{"name":{"S":"製品B"},"valid_series_list":{"L":[{"S":"22"},{"S":"23"}]}}}}' --profile example
aws dynamodb put-item --table-name master --item '{"code":{"S":"C"},"info":{"M":{"name":{"S":"製品C"},"valid_series_list":{"L":[{"S":"22"},{"S":"23"}]}}}}' --profile example
問題点
ただ、これまでのやり方には色々と問題点がありました。
- 環境(テスト環境や本番環境など)ごとにテーブル名やプロファイル名が異なるので、
環境分のコマンドを用意しなくてはならない - 手作業でコマンドを打つので、作業ミスが怖い
コマンド準備⇒コマンド実行の一連の手順が単純に面倒くs(おっとあなたは何も見ていません⚠️)
もうちょい良い感じにできないかな
そこでシェルスクリプトを作成!!・・・しても良かったのですが、
ふと「もしかしてアレが使えるんじゃないか」と思い付きました。
アレとは、AWSハンズオンでやった「S3 トリガーを使用してLambda関数を呼び出す」という設計パターンです。
「せっかく研修で習ったんだし、そっち使ってみたいー!」と思い、
TechLに相談したら「いいよ~やってみ~」と快諾してくれました🎉
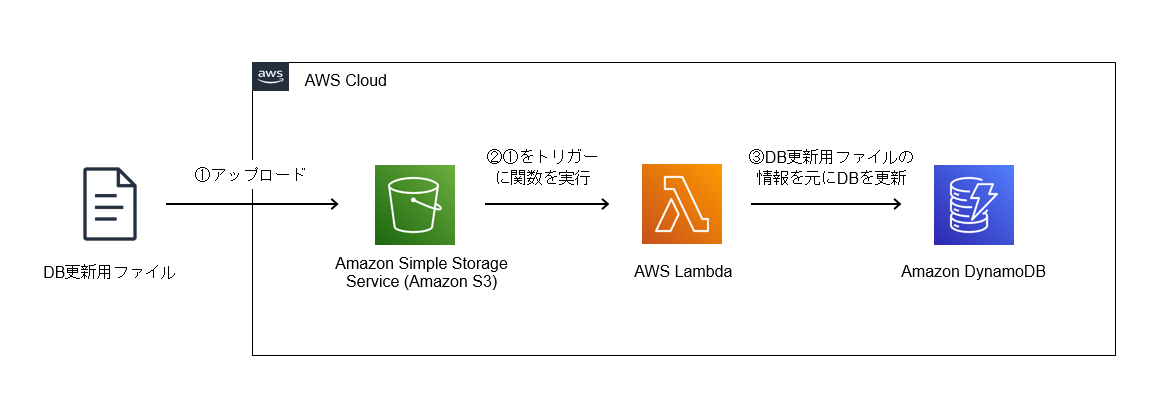
作成したシステム
概要は以下の図の通りです。
具体的な設定など
1つ1つご紹介します。
●DB更新用ファイル
DB更新用ファイル作成のポイントはたった2つです。
- 環境差異をなくす
(テーブル名の情報はLambda関数側で保持させます。プロファイル名はCLIじゃないので不要) - DynamoDB自体がkey-value データベースなので、それに合わせてjsonにする
例:「update.json」
{
"A": {"M": {"name": {"S": "製品A"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}},
"B": {"M": {"name": {"S": "製品B"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}},
"C": {"M": {"name": {"S": "製品C"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}}
}
●S3バケット
DB更新用ファイルを配置するためのバケットを作成します。
今回は「master-update」というバケットを作りました。
●Lambda関数
S3トリガーのLambda関数を作ります。
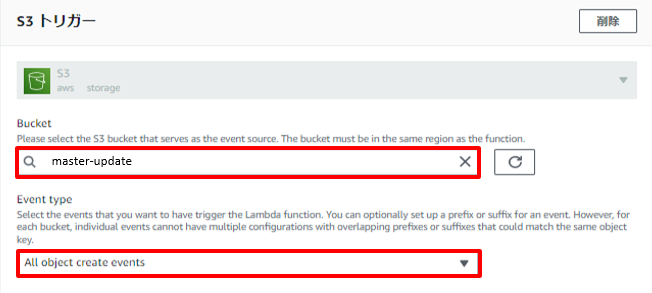
環境変数を設定しておきます。(テーブル名、S3バケット名、DB更新用ファイル名)
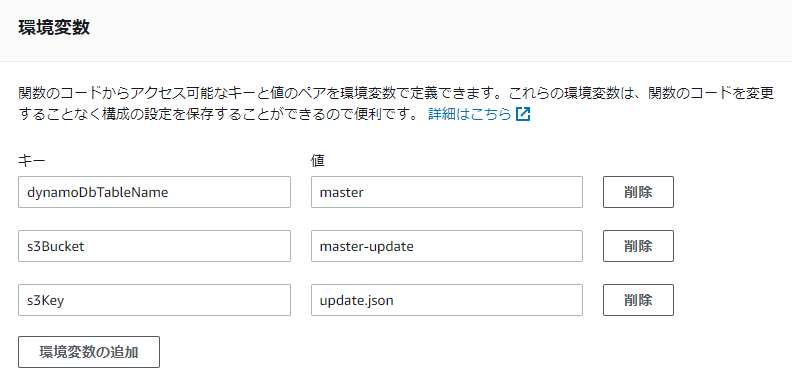
コード:
console.log("Loading function"); const aws = require("aws-sdk"); const s3 = new aws.S3({ apiVersion: "2006-03-01" }); const dynamoDb = new aws.DynamoDB(); exports.handler = async (event) => { const tableName = process.env.dynamoDbTableName; const data = await s3.getObject( { Bucket: process.env.s3Bucket, Key: process.env.s3Key }).promise(); const obj = JSON.parse(data.Body); const items = []; Object.keys(obj).forEach(function (key) { items.push({ Update: { TableName: tableName, Key: { "code": { "S": key }}, UpdateExpression: 'set info = :info_new', ExpressionAttributeValues: { ':info_new': obj[key] } } }); }); try { // トランザクション開始 await dynamoDb.transactWriteItems({ TransactItems: items }).promise(); // トランザクション終了 console.log("全項目更新完了"); } catch (err) { console.error(err); console.error("更新失敗"); } };
●IAMロール
以下のポリシーがアタッチされたロールをLamdbaにアタッチします。
①DB更新用ファイルの読み込み(許可)
②DynamoDBの「master」テーブルのアイテムの更新(許可)
③CloudWatch Logs へのログのアップロード(許可)
以上がこのシステムに必要な設定です。
動かしてみる
実際に試してみます。
変更前のテーブルがこちら。
①DB更新用ファイルを用意し、
{
"A": {"M": {"name": {"S": "製品A"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}},
"B": {"M": {"name": {"S": "製品B"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}},
"C": {"M": {"name": {"S": "製品C"},"valid_series_list": {"L": [{"S": "22"},{"S": "23"}]}}}
}
②S3バケットにアップロードします。

③すると、CloudWatchにLambda関数が動いたログが出ました。
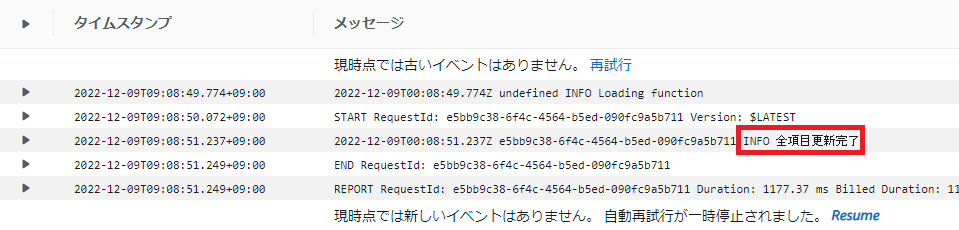
④DynamoDBを確認。どきどき。
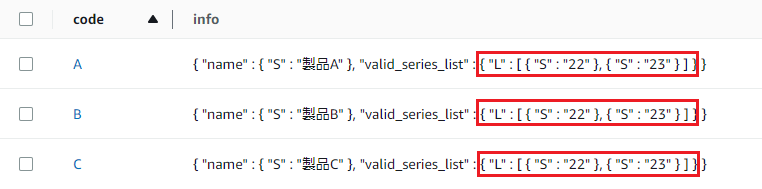
はい、ちゃんと更新されています!!!(わーい🙌)
という風に、あっという間に任務は完了です。
また次の更新時期がやって来ても、DB更新用ファイルを編集してアップロードすればOKというわけです!!
あ~~楽だ~~~~🐪最高~~~~~~!!!
やってみての感想
はい。というわけで、研修で習った技術を使いつつ、無事DynamoDBの更新作業の効率化を達成することができました。
このシステムの作成を通して、今回使用したリソース(DynamoDB、Lambda、S3、IAM)については、
研修で習った時よりもかなり理解が深まったなぁと感じています。
(練習環境で失敗を恐れずに色々と試せたのが大きかったです!)
また、小規模のシステムではあるものの「AWSを実務で使えたぞ!!」という自信がついたので、
今後はAWSのその他の主要リソースについても実践を交えながら勉強して、もっと複雑なアーキテクチャをAWSで実現できるようになりたいと思っています💪🔥
あと、このシステムを作った時に、チームの人に感謝してもらえたのは何気にかなり嬉しかったです。
お客さまのために仕事を頑張っていくのはもちろんですが、
一緒に働くチームの皆さんが楽をできたりミスを減らせたりするようなツールを作っていくのも、今後頑張っていきたいと思いました!
おわりに
いかがでしたでしょうか?
明日12月23日の弥生 Advent Calendar 2022は、AWS 最大のラーニングカンファレンス「re:Invent 2022」に参加された鍋谷さんによる記事です!どうぞお楽しみに!